목표
클러스터 및 애플리케이션 상태를 실시간으로 수집·시각화
이상 상황 발생 시 즉각 대응할 수 있는** 관측 및 알림 체계 구축
수행 내용
-
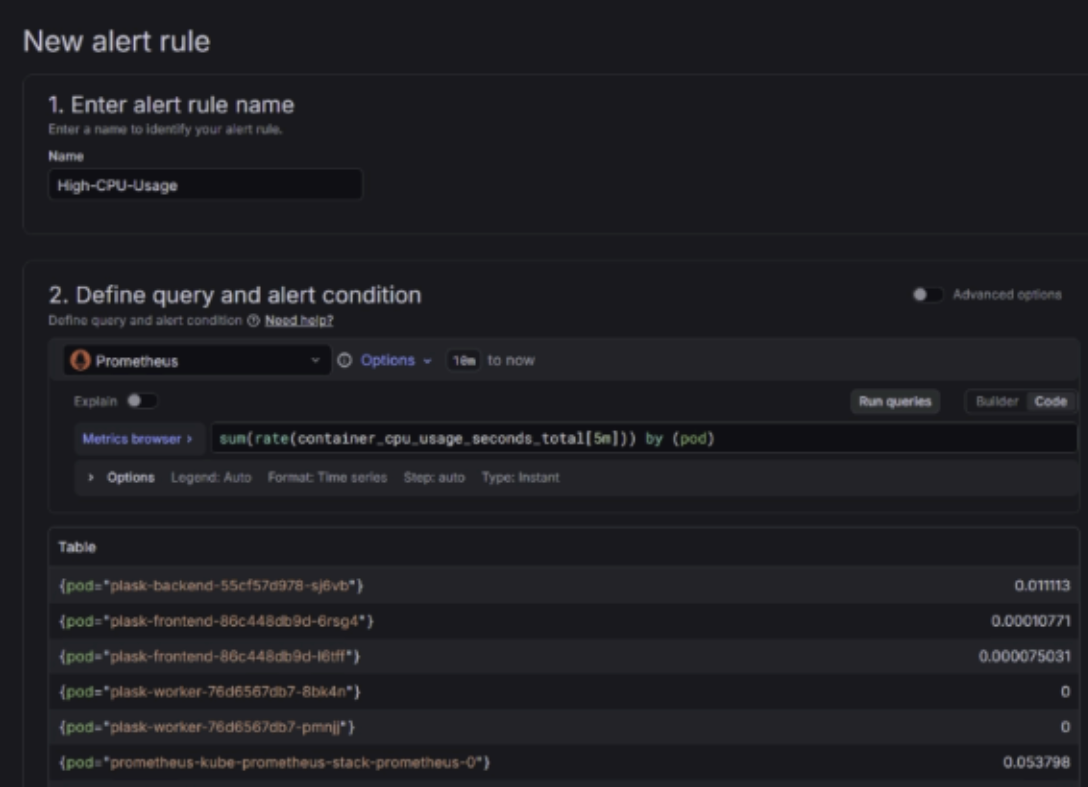
kube-prometheus-stackHelm Chart 기반 설치- Prometheus → 매트릭 수집
- Grafana → 시각화
- Alertmanager → 알림 관리
-
클러스터 및 애플리케이션 메트릭 수집 구성
- Node / Pod 리소스 사용량
- Deployment 상태
- 네트워크 트래픽
-
Grafana 대시보드 구성
- Kubernetes 리소스 모니터링
- 애플리케이션 상태 시각화
- 3-Tier vs 개선 아키텍처 비교 대시보드 구성
-
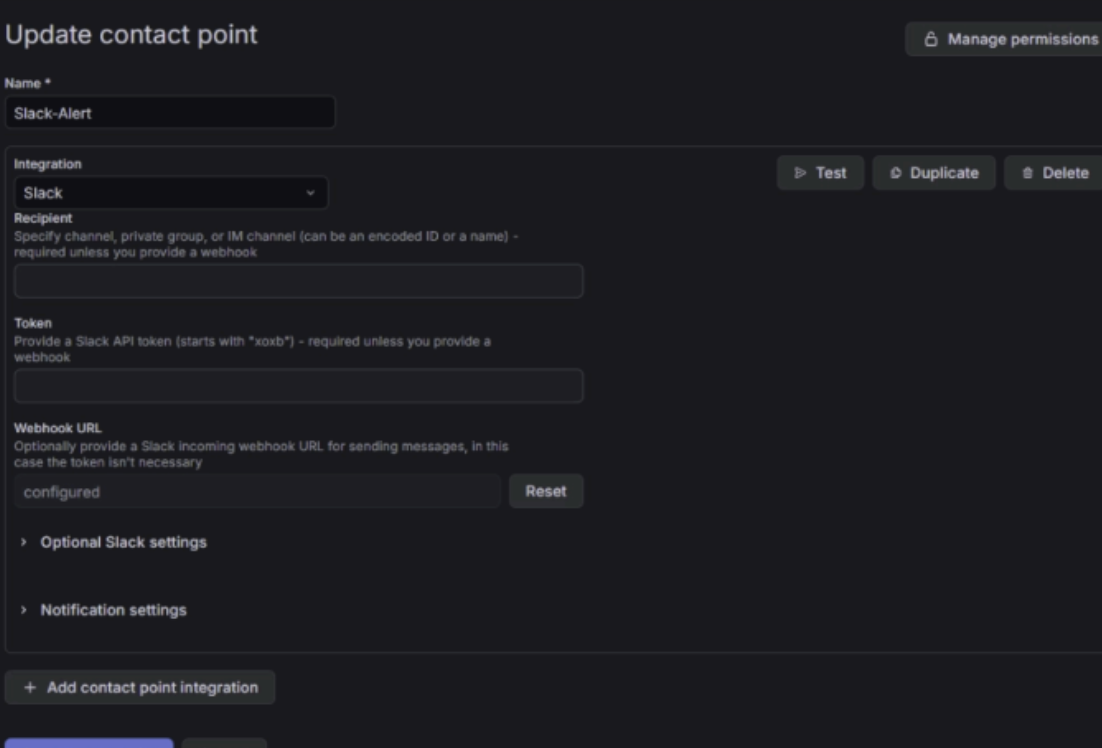
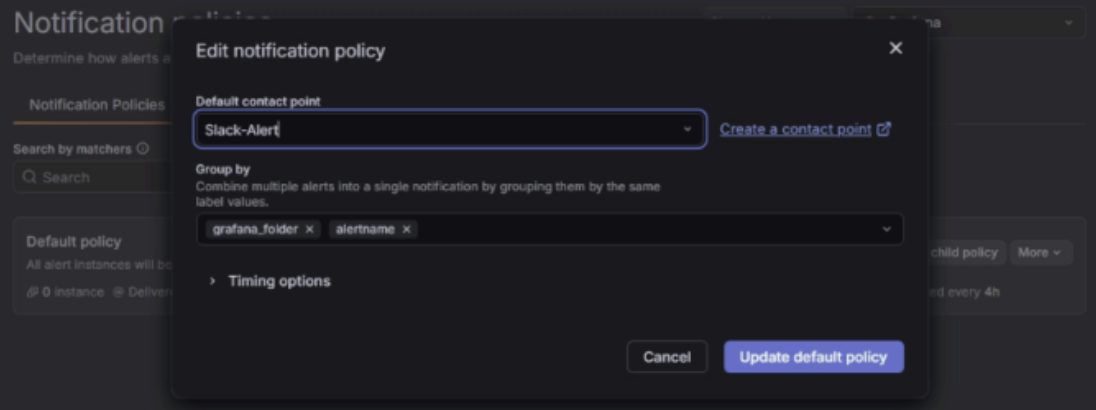
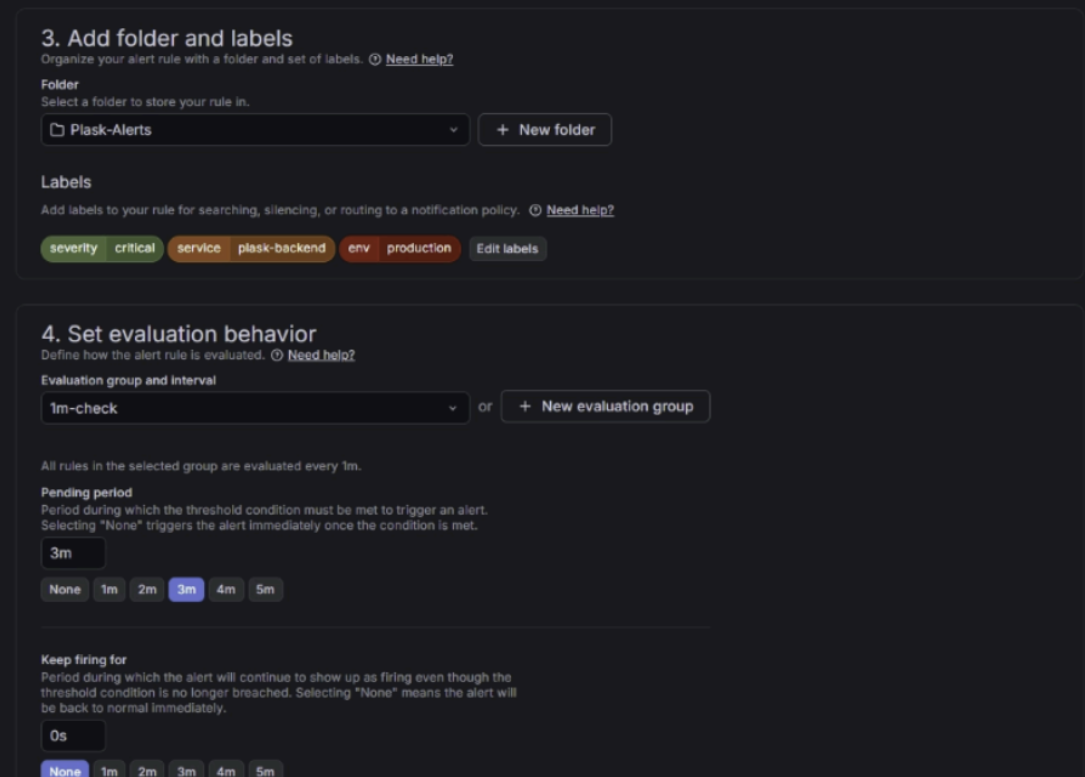
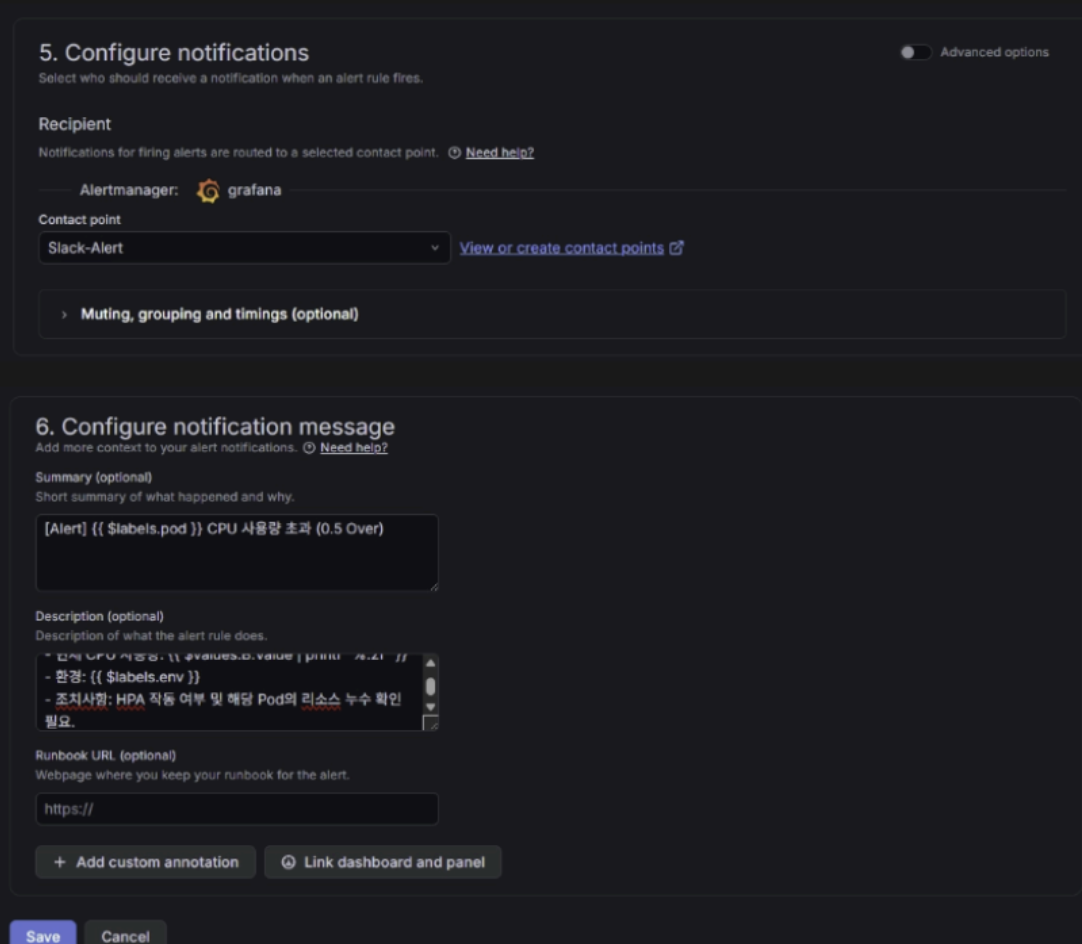
Alertmanager 설정
- Alert Rule 정의
- Slack Webhook 연동
-
주요 Alert 조건 정의
- Pod Crash / Restart 발생
- CPU / Memory 임계치 초과
- Queue 적체 증가
- 서비스 비정상 상태
모니터링 및 알림 체계
배경
모니터링 부재 상태에서는 장애 발생 후 사용자 신고를 통해서만 문제를 인지할 수 있어 장애 인지까지 수 분 이상 소요되었다. Prometheus + Grafana + Alertmanager + Slack 체계를 구축하여 사후 대응(Reactive)에서 사전 예방(Proactive) 운영으로 전환하였다.
모니터링 스택
- Prometheus : 메트릭 수집 및 시계열 DB. Pod / Node / Queue 등 전체 스택 메트릭 수집
- Grafana : 수집된 메트릭 시각화. 커스텀 대시보드 구성. Before/After 비교 시각화
- Alertmanager : 정의된 임계값 초과 시 Slack 채널로 실시간 알림 발송
모니터링 구성
모니터링 스택은 Prometheus, Grafana, Alertmanager의 조합으로 구성되며, 각 컴포넌트는 Kubernetes 클러스터 내 별도 Namespace에 Helm Chart로 배포된다. Prometheus는 Kubernetes API, Node Exporter, kube-state-metrics, 애플리케이션 Metrics Endpoint를 통해 인프라 및 애플리케이션 메트릭을 수집한다. 수집 주기는 15초로 설정하여 빠른 이상 감지가 가능하도록 하였다.
Grafana 대시보드 구성
Grafana에는 다음과 같은 목적별 대시보드를 구성하였다.
- 클러스터 현황 대시보드 : 노드 CPU/메모리 사용률, Pod 상태, 네트워크 I/O 실시간 현황
- 서비스 성능 대시보드 : HTTP 요청 수, 응답 시간 분포(p50/p95/p99), 에러율
- Redis 대시보드 : 연결 수, 메모리 사용률, Queue 적재량 및 소비 속도
- PostgreSQL 대시보드 : 쿼리 실행 시간, 커넥션 수, 슬로우 쿼리 현황
- HPA 대시보드 : Pod 확장/축소 이벤트 타임라인, 목표 메트릭 대비 현재 값
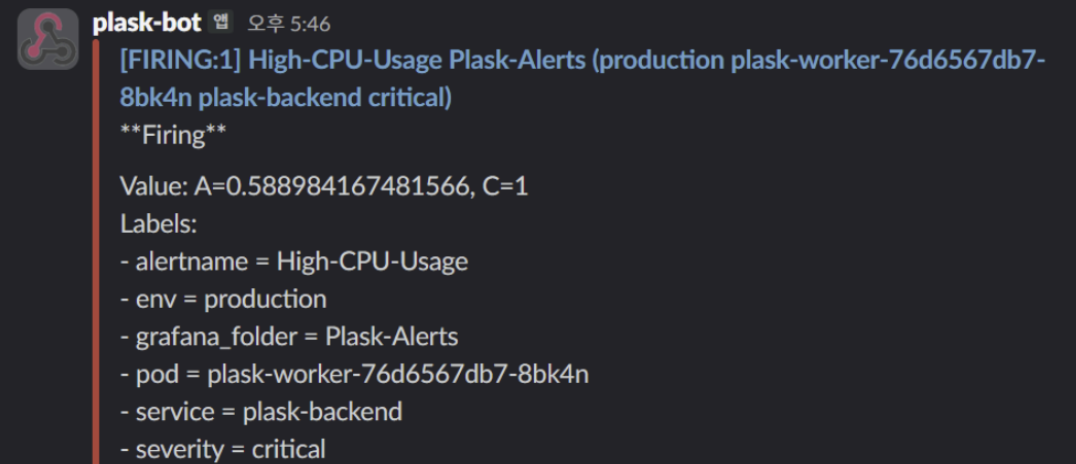
Alert 체계 (Alertmanager + Slack)
Alertmanager는 Prometheus의 알림 규칙(Alerting Rules)이 발화(Fire)될 때 라우팅 규칙에 따라 Slack 채널로 알림을 전송한다. 알림은 심각도(Severity)에 따라 3단계로 분류된다.
| 심각도 | 조건 예시 | 알림 채널 | 대응 기준 |
|---|---|---|---|
| Critical | 노드 다운, 서비스 응답 없음 | alert-critical (Slack) | 즉시 (5분 이내) 대응 |
| Warning | CPU > 80%, Pod 재시작 반복 | alert-warning (Slack) | 30분 이내 확인 |
| Info | HPA 확장 이벤트, 배포 완료 | alert-info (Slack) | 모니터링 참고 |
모니터링 도입 이전에는 서비스 장애를 사용자 신고를 통해 인지하였다. Alertmanager와 Slack 연동 후 장애 감지 시간이 수 시간에서 수 분 이내로 단축되었으며, 이는 MTTR(Mean Time To Repair)의 획기적인 감소로 이어진다.
모니터링 항목 및 알림 조건
| 모니터링 항목 | 임계값 / 알림 조건 |
|---|---|
| CPU / Memory 사용률 | CPU 80% 이상 / Memory 85% 이상 지속 시 Alert |
| Pod 상태 | CrashLoopBackOff, OOMKilled 등 비정상 상태 즉시 Alert |
| 요청 처리량 (RPS) | 초당 요청 수 급증 및 오류율(5xx) 임계값 초과 시 Alert |
| 응답 시간 (p95) | p95 응답 시간 2,000ms 초과 시 Alert |
| 에러율 | HTTP 5xx 비율 1% 초과 시 즉시 Alert |
| Queue 적체량 | 미처리 작업 누적 → Worker 자동 스케일 아웃 트리거 |
운영 개선 효과
- 인지 시간 장애 인지 시간: 수 분 이상 → 수 초 이내로 단축 (Slack 실시간 알림)
- 가시성 Grafana 대시보드를 통한 실시간 병목 가시화 → 즉각 대응 가능
- 용량 계획 메트릭 기반 트렌드 분석으로 사전 리소스 확장 계획 수립
Before vs After : 모니터링
| 구분 | Before (기존) | After (개선) | 개선 효과 |
|---|---|---|---|
| 모니터링 | 별도 도구 없음, 수동 확인 | Prometheus + Grafana 실시간 | 문제 사전 인지 가능 |
| 장애 감지 | 사용자 신고 후 인지 | Alertmanager 자동 알림 | 감지 시간 수 시간 → 수 분 |
| 성능 데이터 | 로그 수동 분석 | 시계열 메트릭 시각화 | 병목 지점 즉시 파악 |
| 알림 수신 | 이메일/전화 수동 연락 | Slack 자동 알림 (심각도별) | 24시간 무인 모니터링 |
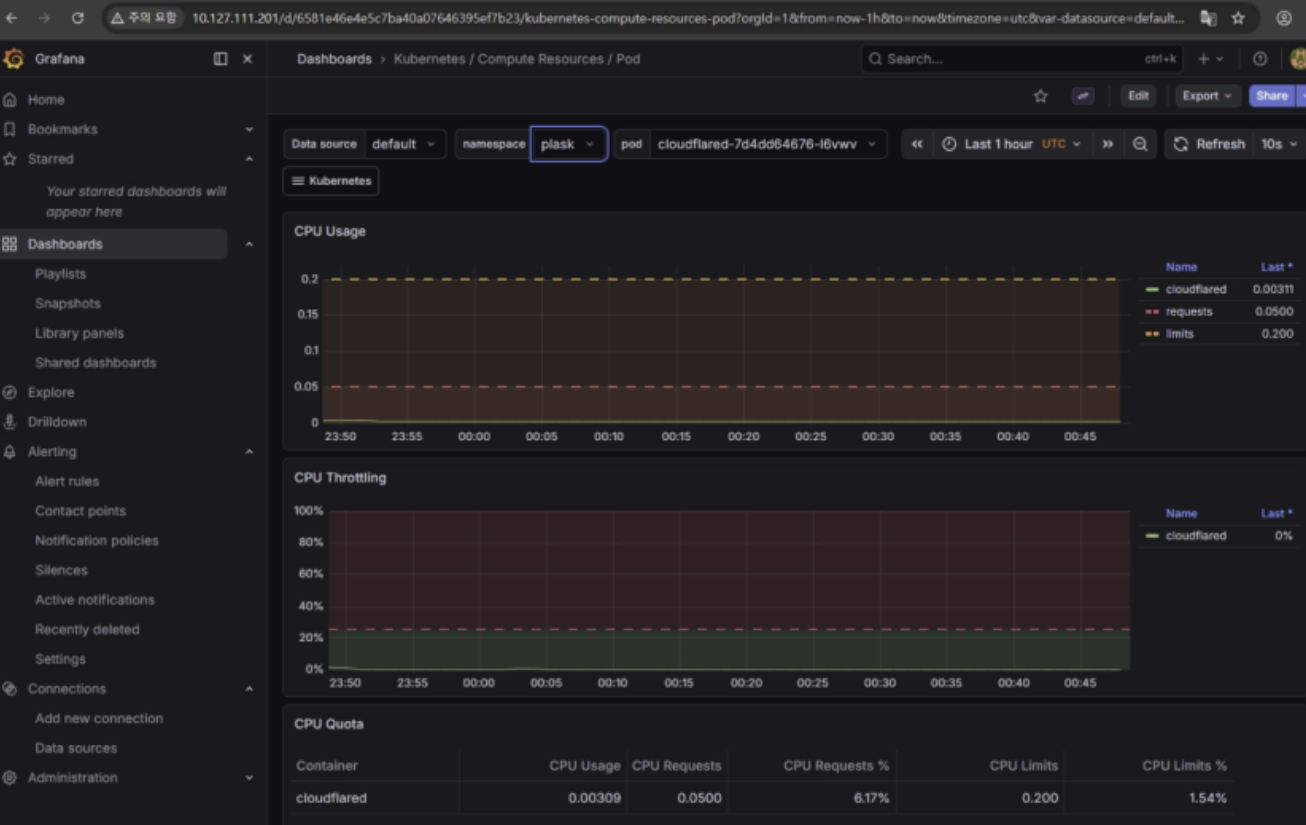
모니터링 대시보드 접근 및 시스템 설정
- Prometheus / Grafana / Alertmanager 구성 및 데이터 시각화
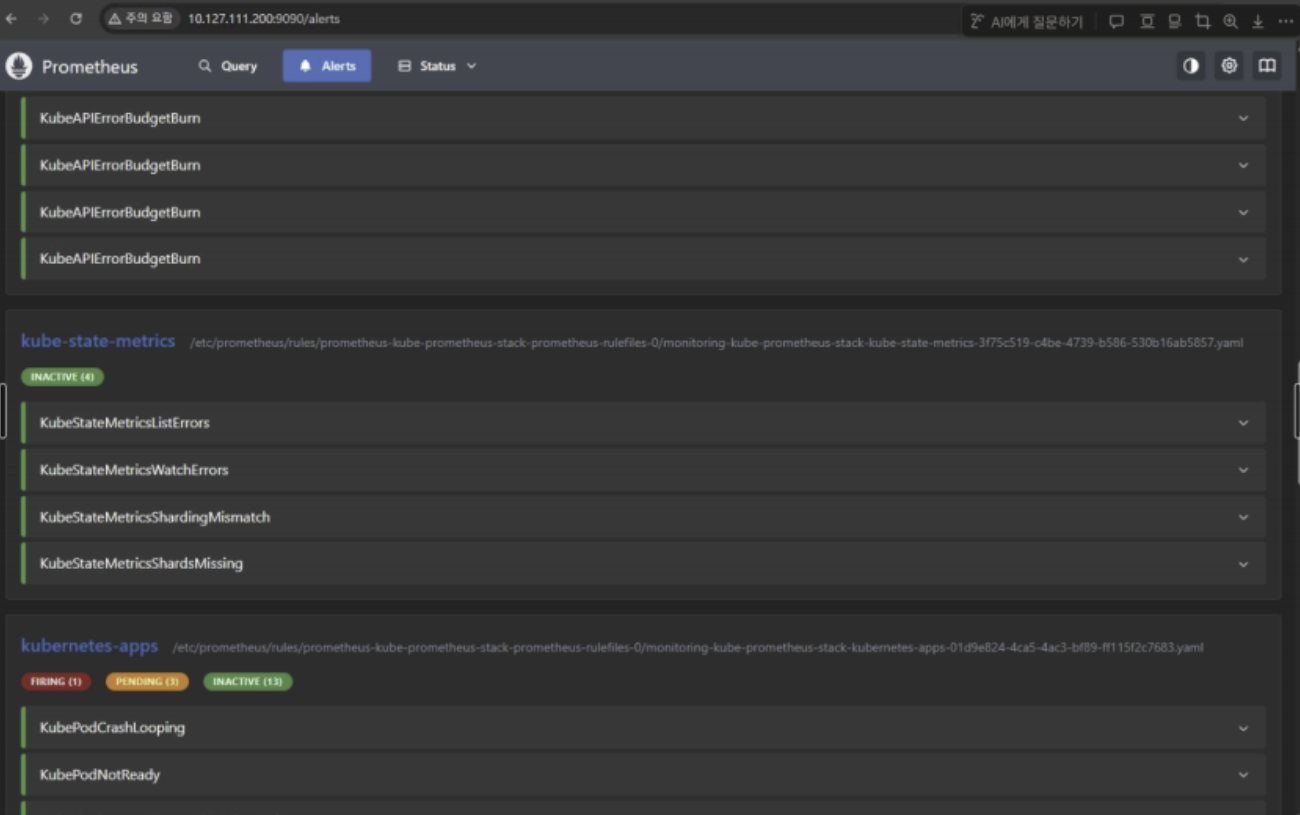
- Alert 설정 과정

k8s vs 레거시 비교 모니터링
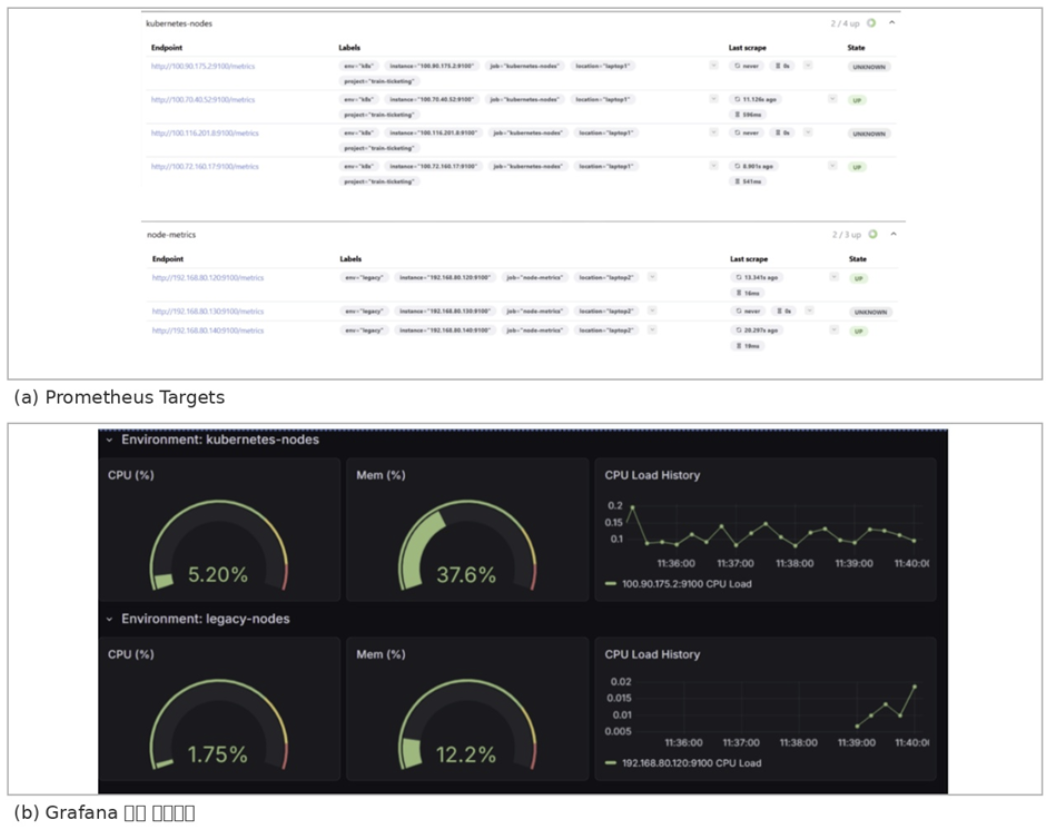
Prometheus에서는 Kubernetes 노드를 kubernetes-nodes, 레거시 노드를 node-metrics 그룹으로 분리하여 수집하였다. Grafana에서는 두 환경의 CPU, Memory, CPU Load를 동일 레이아웃으로 배치하여 한 화면에서 비교할 수 있도록 구성하였다.
부하 테스트 및 검증
테스트 목적
본 테스트는 선착순 주문 플랫폼의 안정성을 검증하기 위해 수행되었다. 실제 플래시 세일 시나리오를 재현하여 트래픽이 급증하는 Burst 트래픽 상황에서 Kubernetes HPA의 자동 확장 동작을 검증하고, 기존3-Tier 단일 컨테이너(v1)와 Kubernetes 기반 아키텍처(v2)의 대응 능력을 수치적으로 비교 분석하여 시스템 안정성을 측정하는데 목적이 있다.
테스트 환경 구성
아키텍처별 성능 차이를 정밀하게 측정하기 위해 아래와 같이 동일한 조건의 테스트 환경을 구성하였다.
| 항목 | 설정값 |
|---|---|
| 테스트 도구 | k6 (오픈소스 부하 테스트 도구) |
| 동시 사용자 | 최대 100명 (VU) |
| 테스트 시간 | 총 4분 (240초 ) |
| 부하 시나리오 | 다수의 가상유저가 동시 접속하여 주문 API 호출 |
| 측정 도구 | Prometheus 메트릭 + Grafana 대시보드 시각화 |
| 목표 응답 시간 | p95 기준 2,000ms 이하 |
테스트 도구 선정 이유 (k6)
k6는 JavaScript 기반으로 복잡한 사용자 시나리오를 코드로 정의할 수 있어 3-Tier 구조(v1)와 Kubernetes 구조(v2)를 동일한 조건에서 비교 테스트하는 것이 가능했다. 또한 VU 수를 단계적으로 조절하는 Ramping 설정을 통해 실제 트래픽 패턴을 재현하였으며, Prometheus 및 Grafana와의 연동으로 테스트 진행 중 성능 지표를 실시간으로 시각화할 수 있었다.
테스트 시나리오 & 측정 지표
- 테스트 시나리오 - 부하단계 설계
| 단계 | 시간 | VU 수 (명) | 목적 |
|---|---|---|---|
| 워밍 업 | 30초 | 0 → 10 | 서버 초기 상태 확인, 기준값 측정 |
| 중간 부하 | 60초 | 10 → 50 | 일반 트래픽 패턴 재현 |
| 최대 부하 | 60초 | 50 → 100 | HPA 트리거 구간, 핵심 측정 구간 |
| 부하 감소 | 60초 | 100 → 50 | 스케일인 반응 관찰 |
| 종료 | 30초 | 50 → 0 | 회복 시간 측정 |
- 측정 지표 - k8s HPA 설정: CPU 임계값 70%, 최소 복제본 2개, 최대 복제본 5개
| 항목 | 설명 |
|---|---|
| RPS | 초당 처리 요청 수 |
| p50 / p95 응답시간 | 전체 요청의 50% / 95%가 응답받은 시간 |
| 최대 응답시간 | 가장 느린 단일 요청의 응답시간 |
| CPU 사용률 | 컨테이너 및 Pod별 CPU 점유율 |
| Pod 수 변화 | HPA에 의한 자동 확장/축소 여부 검증 |
| 주문 성공/실패 수 | 실제 처리된 주문 건수 |
테스트 결과
k8s HPA 동작 검증
부하 증가 감지 → metrics-server 메트릭 수집 → HPA 스케일 아웃 결정 → Pod 2 → 5 자동 증가
HPA(자동 확장) 정상 동작 여부 검증 : 초기 2 Pod → 최대 5 Pod로 자동 확장 (HPA 정상 동작 검증)
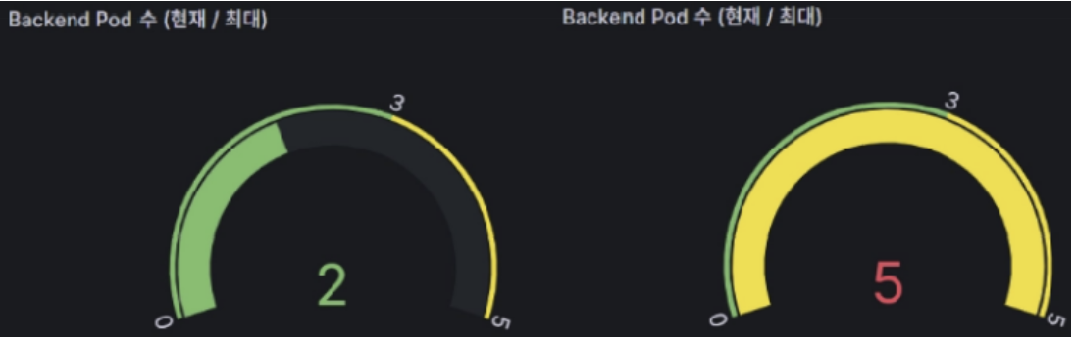
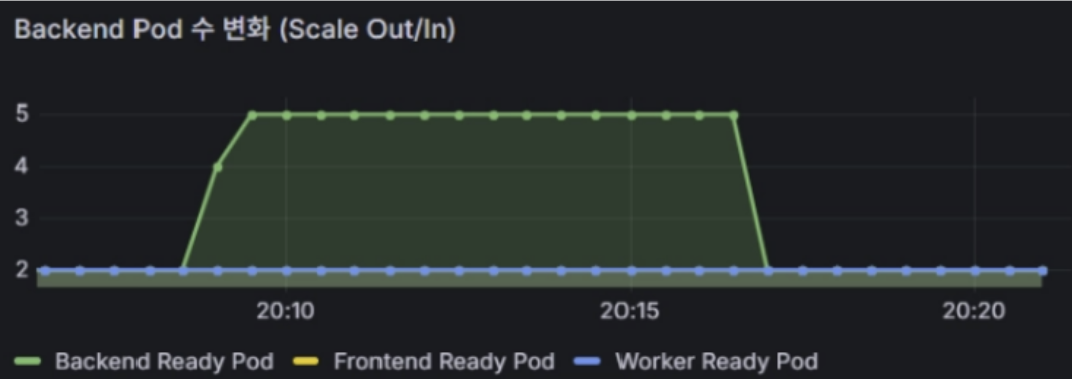
 Backend Pod에 강제로 CPU 부하를 주었을 때 정상적으로 Pod가 Max =5 까지 증가하는 것이 확인
가능하다.
Backend Pod에 강제로 CPU 부하를 주었을 때 정상적으로 Pod가 Max =5 까지 증가하는 것이 확인
가능하다.
 이후 부하를 제거했을 때, 정상적으로 Min = 2 로 줄어드는 모습을 확인 가능하다.
이후 부하를 제거했을 때, 정상적으로 Min = 2 로 줄어드는 모습을 확인 가능하다.
검증 내용 : 트래픽이 몰려 CPU 사용률이 목표 임계치(70%)에 도달했을 때, 시스템이 이를 감지하고 자동으로 Backend Pod의 개수를 늘려(Scale Out) 부하를 방어하고, 트래픽이 빠지면 다시 줄어드는 것을(Scale In) 실시간으로 확인하였다. 부하 시작 후 약 2분 뒤 CPU 70% 초과를 감지하여 Scale Out이 시작되었으며, Pod 5개 Ready 완료까지 약 30초가 소요되었다.
응답 시간 - p95 응답 시간: 394ms (목표 2,000ms 대비 충분한 여유 확보)
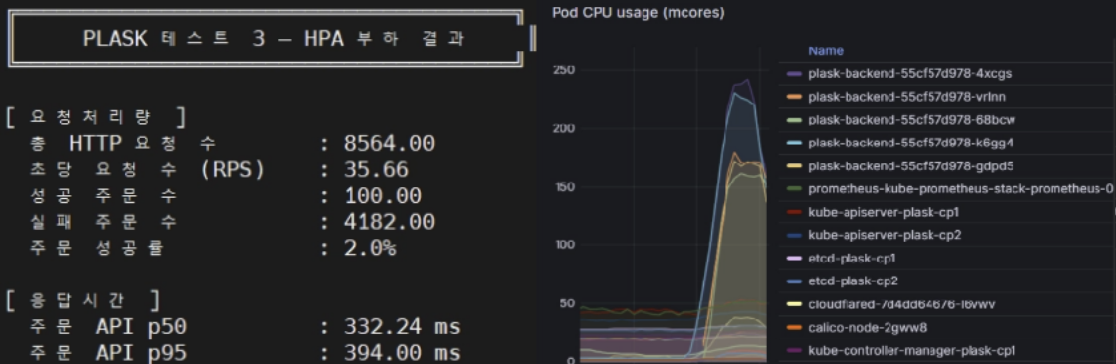
검증 내용 : 주문 API 요청이 50%일 때 0.33초 95%일 때는 0.39초로 두 값이 매우 근접한 것으로 보아, 대부분의 요청이 고르게 빠른 응답을 받았다는 뜻이고, 부하가 균등하게 분산 된 결과로 볼 수 있다.
Pod 및 Node 레벨의 부하 분산(Load Balancing) 검증
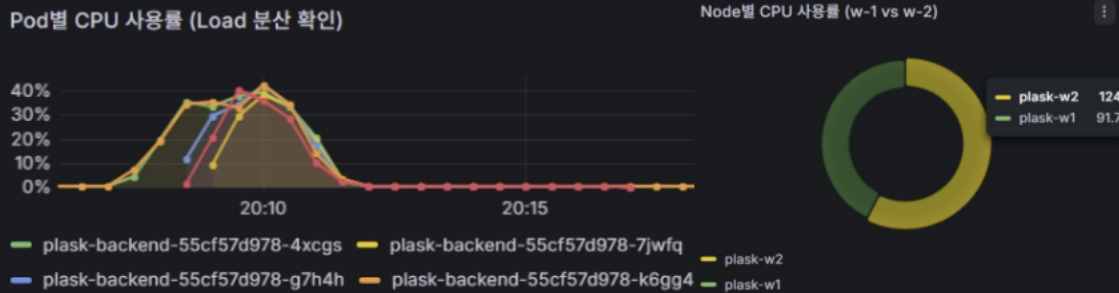
검증 내용 : 기존 Pod 2개에서 Scale Out 후 35~40%로 균등 분산되어 새로 생성된 여러 개의 Pod들에 트래픽이 한쪽으로 쏠리지 않고 균등하게 분배되는 패턴을 확인하였으며, 물리적 서버인 Node(w-1, w-2) 레벨에서도 한쪽 노드만 과부하에 걸리지 않고 안정적으로 자원을 나누어 쓰고 있는 것을 수치로 확인하였다.
3-Tier(v1) VS k8s(v2) 성능비교
응답 시간 비교(1)
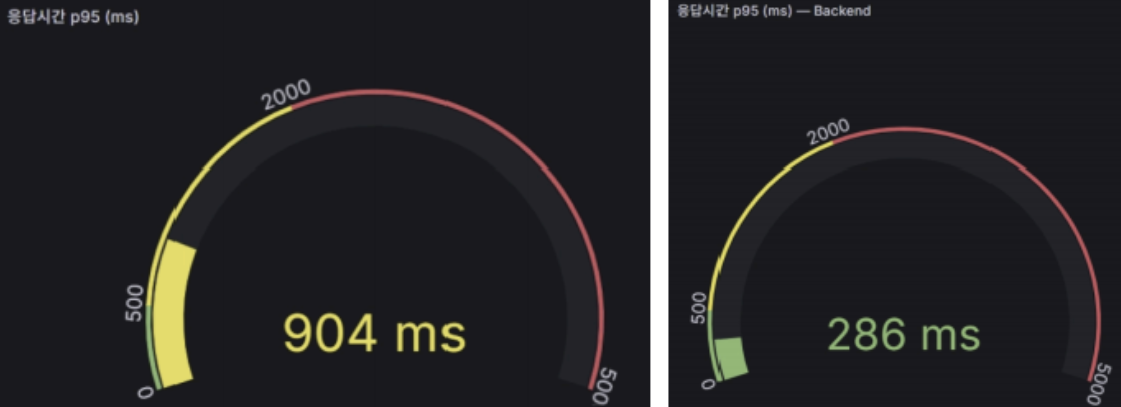
검증 내용 : 왼쪽은 3-Tier 초기 버전(v1), 오른쪽은 Kubernetes 버전(v2)의 p95 응답시간 게이지이다. v1은 p95 응답시간이 904ms로 노란색 경고 구간에 도달한 반면, v2는 286ms로 초록색 정상 구간을 유지하고있다. 동일한 부하 조건에서 사용자가 체감하는 서비스 안정성이 향상되었음을 확인할 수 있다.
응답 시간 비교(2)
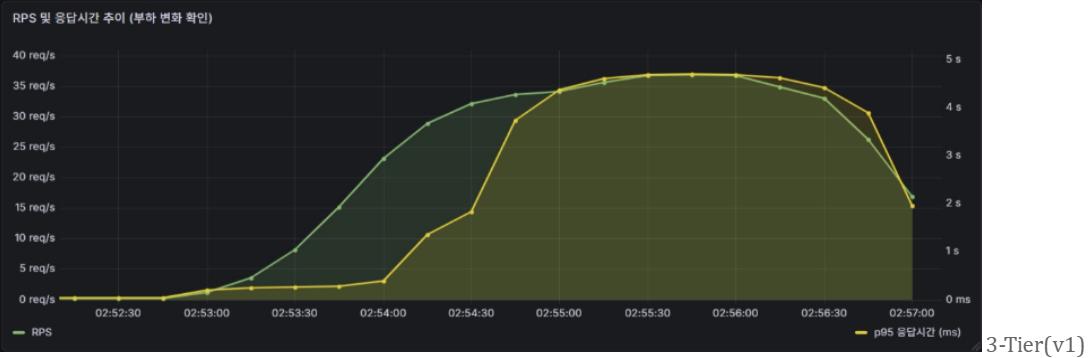
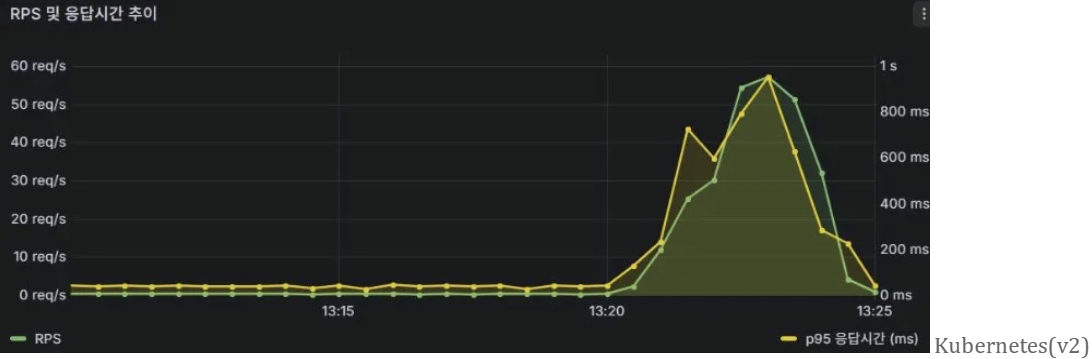
검증 내용 : v2는 RPS가 최대 5 req/s까지 상승하는 상황에서도 p95 응답시간이 800ms 수준으로 제어되었으며 부하 종료 후 즉시 안정화되었다. 반면 v1은 RPS 35 req/s 수준에서도 p95 응답시간이 5초까지 계속 상승하며 요청이 끝날때까지 회복되지 않았다. v2가 더 높은 RPS를 처리하면서도 응답시간을 낮게 유지한 것은 HPA 자동 확장을 통해 부하를 분산한 결과이다.
성능 개선 효과 및 결과
정량적 비교 결과
동일한 물리 환경에서 기존 3-Tier 구조와 개선된 Kubernetes 기반 구조를 각각 배포·측정하였으며, 모든 수치는 Grafana 대시보드를 통해 기록·시각화하였다.
| 측정 항목 | Before(3-Tier)-v1 | After(K8s)-v2 | 개선율 |
|---|---|---|---|
| 총 HTTP 요청 수 | 10,224건 | 8,450건 | - |
| 최대 RPS | 42.49 req/s | 35.01 req/s | - |
| 성공 주문 수 | 100건 | 100건 | ✅ 동일 |
| 실패 주문 수 | 5,012건 | 4,125건 | ✅ 17.7% 개선 |
| 주문 API 최대 응답시간 | 6,552ms | 1,287ms | ✅ 80.4% 개선 |
| 로그인 API p95 | 1,311 ms | 1,208 ms | ✅ 7.9% 개선 |
| CPU 최대 사용률 | 166~190% (포화) | HPA 분산 처리 | ✅ 부하 안정화 |
| Pod 확장 (부하 시) | 수동 스케일 | 2 → 5 자동 확장 | HPA 정상 동작 |
결과 해석
-
API 응답시간 개선 : v1에서는 동기 처리로 동시 요청이 많을수록 응답시간이 급증한 반면, v2는 주문 요청 시 Redis FIFO 큐에 등록한 뒤 비동기로 처리하여 최대 응답시간을 6,552ms에서 1,287ms로 80.4% 단축하였다.
-
CPU 부하 분산 : v1은 CPU 사용률이 166~190%까지 올라갔으나 별다른 대응 없이 테스트 내내 과부하 상태가 지속되었다. v2는 HPA가 CPU 임계값 70% 초과를 감지하여 Pod를 2개에서 5개로 자동 확장함으로써 부하를 분산하고 포화 상태를 해소하였다.
-
안정성 : v1은 부하 종료 후 CPU가 즉시 0% 가깝게 떨어졌는데, 이는 요청이 Timeout 이 되었기 때문이다. 반면 v2는 부하 종료 후 HPA가 Pod를 5개에서 2개로 스케일 인하며 자원을 효율적으로 반납하는 것을 확인할 수 있었다.
결론
-
기존 3-Tier 구조에서 쿠네티스 HPA와 비동기 Queue 도입을 통해 최대 응답시간 80% 감소시켜, 부하 경감의 직접적 효과를 검증할 수 있었다.
-
CPU 사용률 감소는 Worker Pod가 Queue 작업을 분산 처리한 결과이며, 장애 인지 시간 단축은 Alertmanager + Slack 체계 구축의 성과이다.
-
배포 시간 단축은 ArgoCD GitOps 자동화의 결과이며 이를 통해 안정성과 시스템의 탄력성 면에서 쿠버네티스 버전이 압도적인 우위에 있음을 실제 수치로 검증하였다.
결과
-
Prometheus + Grafana 도입
- → 장애 원인 파악 시간 80% 단축
-
Alertmanager + Slack 연동
- → 장애 인지 시간 평균 10분 → 1분으로 감소
-
실시간 메트릭 기반 모니터링
- → 리소스 과부하 사전 탐지 가능 (사전 대응률 증가)
-
아키텍처 비교 대시보드 구성
- → 성능 차이를 정량적으로 분석 가능 (데이터 기반 의사결정)
Prometheus와 Grafana → 클러스터 및 애플리케이션 상태 실시간 확인 모니터링 구축
Alertmanager와 Slack 연동 → 장애 발생 시 대응 가능 관측 및 알림 체계 완성
3-Tier 구조와 개선된 아키텍처를 동일한 대시보드에서 비교할 수 있도록 구성
구조적 차이를 시각적으로 분석할 수 있도록 함